There cannot be many mature products where development meetings have not been interrupted with a rueful declaration that to make further progress “you wouldn’t start from here”. This encapsulates one key difference between the architect and engineer, the latter prepared to work with the set of tools provided, the other preferring to start with a blank sheet of paper or an open space.
In building research data repositories using two different softwares, Microsoft Sharepoint and EPrints, the DataPool Project is working somewhere between these extremes. Which approach will prove to be the more resilient for research data management (RDM)? In this invited talk for RDMF 9, the ninth in the DCC series of Research Data Management Forums, held in Cambridge on 14-15 November 2012, we will look at the relevant factors. As a project we are agnostic to repository platforms, and as an institutional-scale project we have to work with who will support the chosen platform.
The original Powerpoint slides are available from the RDMF9 site. This version additionally reproduces the notes for each slide used to inform the commentary from the presentation. It might be worth opening the Slideshare site (adverts notwithstanding) to switch between the slide notes below and the graphic slides – clicking on View on Slideshare in the embedded view will open these in a separate browser window
I thank Graham Pryor of DCC, organiser of RDMF9, for inviting this talk, and for suggesting this topic based, presumably, on the project blog post shown in slide 2. This post sets out some of the higher-level issues while avoiding the trap of setting up a straw man pitting Sharepoint versus EPrints.
Before we get into the detailed notes, here is the live Twitter stream for the DataPool presentation (retrieved from #rdmf9 hashtag on 15 Nov.).
@jiscdatapool Preparing to talk at #rdmf9. Have the 9 am slot
@MeikPoschen #rdmf9 2nd day: To architect or engineer? Lessons from DataPool on building RDM repositories, first talk by Steve Hitchcock #jiscmrd
@MeikPoschen JISC DataPool Project at Southampton, see t.co/g5FCfkhB #jiscmrd #rdmf9
@simonhodson99 Down to work at #rdmf9 at Madingley Hall – outside it’s misty, autumnal – inside it’s Steve Hitchcock, DataPool: to architect or engineer?
@simonhodson99 Steve Hitchcock argues that the DataFlow t.co/RQqp8VdQ solution is one of the most innovative things to come through #jiscmrd #rdmf9
@simonhodson99 ePrints data apps available from ePrints Bazaar: t.co/d1zk8oD1 #jiscmrd #rdmf9
@jtedds Hitchcock (Southampton) describes institutional drive to implement SharePoint type solution but can it compete with DropBox? #jiscmrd #rdmf9
@jtedds Trial integrations with DataFlow MT @simonhodson99 ePrints data apps available from ePrints Bazaar t.co/4X8pv9iz #jiscmrd #rdmf9
@John_Milner Hitchcock highlights the challenge of getting quality RDM while keeping deposit simple for researchers, not easy #RDMF9
@simonhodson99 Perennial question of the level of detail required in metadata: with minimal metadata will the data be discoverable or reusable? #rdmf9
@simonhodson99 Is SharePoint a sufficient and appropriate platform for active data management? Sustainable? One size fits all? #rdmf9
Are the Twitter contributions a fair summary? We return to the slide commentary to find out.
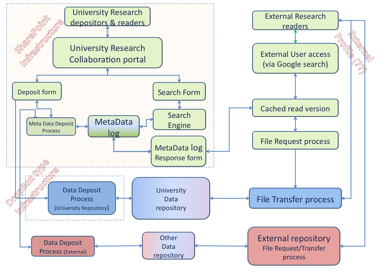
Slide 3 The blog post highlighted in slide 2 included this architectural diagram, produced by Peter Hancock, director of the iSolutions IT services provider at the University of Southampton. Although it leans heavily towards referencing Sharepoint, it can be viewed as a high-level reference model, analogous to the OAIS in digital preservation, and therefore as a model that can embrace other repository types.
Slide 4 Before we get into the detail of the presentation, here is a poster-based summary of the DataPool Project. It has a tripartite approach characteristic of similar institutional projects in the JISC MRD programme, covering data policy, training and, the area of interest here, building a data repository. It is worth noting as well, in this context, that the development partners shown in the row beneath the tripartite elements effectively represent ways of getting data in and out of the RDM service adopted, and are relevant factors in the repository design.
Slide 5 Here is how the different repository platforms might line up on a broad spectrum of Architected vs Engineered. This is a rough-and-ready approach to illustrate the basic point. Also included is DataFlow, from the University of Oxford, perhaps the most innovative repository platform to have emerged for RDM. Given its originality, it appears towards the architected end of the spectrum. We could not claim that Sharepoint is a new software platform in the same way as DataFlow, but from an RDM perspective you don’t get anything out of the box – you have to start from scratch and ‘architect’ an RDM solution. What developers can do is try and ‘engineer’ the designed RDM element with the IT services already provided in Sharepoint. EPrints first appeared in 2001 to manage research publications. It has offered a ‘dataset’ deposit type since 2007, so provides a ready-made solution for an RDM repository, and can be ‘engineered’ to enhance that solution. As the slide notes, other RDM repository platforms are available. In the following slides we will explore the features of our three highlighted RDM platforms, starting with DataFlow.
Slide 6 DataFlow is a two-stage architecture for data management: an open (Dropbox-like) space for data producers (DataStage), and a managed and curated repository (DataBank), connected by a standard content transfer protocol, SWORD. While DataBank provides a bespoke data management service for Oxford, we have recently noted experiments to connect an open source version of DataStage with EPrints- and DSpace-based curated repositories, thus providing the yearned for Dropbox functionality apparently so in demand with research data producers.
Slide 7 This is an example screenshot from the DataStage-EPrints experimental arrangement used by the JISC Kaptur project. It shows the familiar Choose File-Upload button combination familiar to e.g. WordPress blog users, for uploading data. Uploaded data is then shown in a conventional file manager list.
Slide 8 To move data from DataStage to the curated repository, again shown in the experimental Kaptur implementation, uses this surprisingly simple SWORD client interface. If this seems insufficient description for a curated item, presumably a more detailed SWORD client could be substituted.
Slide 9 One basis for building a more comprehensive description, or metadata, for research data is this 3-layer model produced by the Institutional Data Management Blueprint (IDMB) Project, the project that preceded DataPool at the University of Southampton. This is quite a general-purpose and flexible model, perhaps with more flexibility than meaning. Structurally, nevertheless, we will see that this has some relevance to repository deposit workflow design.
Slide 10 The 3-layer metadata model can be seen quite clearly in the emerging user interface for data deposit built on Sharepoint. Here we see the interface for collecting project descriptions, used once per project and then linked to each data record produced by the project.
Slide 11 In the same style, here is the Sharepoint user interface for collecting data descriptions. One of the most noticeable features within both the Project and Data forms is the small number of mandatory fields (indicated with a red asterisk), just one on each form. Mandatory fields have to be filled in for the form to submit successfully. Most people will have experienced these fields; invariably when completing a Web shopping form these will be returned with red text warning. In this case you could feasibly submit a project or data description containing only a title. Aspects such as this are shortly to be subjected to user testing and review of this implementation.
Slide 12 Sharepoint has its detractors as an IT service platform, principally bemoaning its complexity-to-functionality ratio. Prof Simon Cox from Southampton University takes the opposite view passionately. This is an extract from his intervention at a DataPool Steering Group meeting (May 2012) putting the case for Sharepoint. It is a good way of understanding the wider strengths of Sharepoint, which may not be immediately apparent to users of particular Sharepoint services. Building the range of services suggested is a difficult and long-term project.
Slide 13 EPrints supports the deposit of many item types, including datasets since 2007. When you open a new deposit process in EPrints you will first be shown this screen, where you can select an item type such as ‘dataset’.
Slide 14 Selecting ‘dataset’ will take you to this next screen, which might look something like this from ePrints Soton, the Southampton Institutional Repository. This is not quite a default screen for standard EPrints installs; the workflow and fields have been customised in some areas by a repository developer.
Slide 15 EPrints users need not be restricted to standard interfaces or interfaces customised to a repository requirement. Interfaces in EPrints can be added to or amended by simply installing an app from the app store, or EPrints Bazaar. Unlike the Apple app store, with which it might optimistically be compared, EPrints apps are not selected to be installed by users but installation is authorised by repository managers. There are already two apps for those managers to choose to suit particular RDM workflow requirements: DataShare and Data Core. More data apps are expected to follow. EPrints is thus being engineered for flexibility in RDM deposit. In the following slides we will explore these first two data apps.
Slide 16 DataShare makes some minor modifications to the default EPrints workflow for deposit of datasets, highlighted with red circles here.
Slide 17 Data Core aims to implement a minimal ‘core’ metadata for datasets. Implementing this app will overwrite the default EPrints workflow, replacing it with the minimal set, approximately half of which is shown here (the remainder in the next slide). In addition, we have a short description of the design aims for Data Core, which are unavailable for Sharepoint data deposit and the DataShare app.
Slide 18 Taking both slides showing the Data Core deposit workflow, this is comparable, in extent, with the Sharepoint ‘data’ interface shown earlier, although it has a few more mandatory fields.
Slide 19 Another example of an EPrints data deposit interface has been developed by Research Data @Essex at the University of Essex. Like Data Core, the Essex approach has explicit design objectives, based on aligning with other metadata initiatives to support multi-disciplinary data. In other words, this does not simply expand or reduce the default EPrints workflow for data deposit, but starts with a new perspective. We have been liaising with its development team to investigate the possibility of building this approach into an Essex EPrints app for other repositories to share.
Slide 20 Here is a section of the Essex workflow, highlighting one area of major difference with the default workflow. It shows fields for time- and geographic-based information.
Slide 21 We’ve looked at getting data into the repository, but not yet how it is displayed as an output, or a data record from the repository. This is one example. It is not the most revealing record, but could be expanded.
Slide 22 Essex has cited specific design criteria for its research data repository. Additionally we have observed some characteristic features, indicated here. In particular, it is a data-only repository, without provision for other data-types offered by EPrints (shown in slide 13). The indication of mandatory fields adds a further layer of insight into the implementation of the design criteria.
Slide 23 So far in this presentation we have seen different implementations of data repository deposit interfaces, including DataFlow, Sharepoint, and multiple interfaces for EPrints. Where is this heading, and what are the common themes? Since we are exploring the difference between architecting and engineering these repositories, I was interested to see this national newspaper article about a major redevelopment of an area close to central London, Nine Elms, an area that interests me as I pass through it on regular basis. Phrases that stand out refer to the relationship between the planned new high-rise buildings. What does this have to do with data repositories?
Slide 24 Interoperability is the relationship between repositories and how they interact with services, such as search, through shared metadata. If repositories have “nothing in particular to do with anything around them” or “show little interest in anything around” them, then they will not be interoperable. If repositories stand alone rather than interoperate then they become less effective at making their contents visible. Open access repositories have long recognised the importance of interoperability, being founded on the Open Archives Initiative (OAI) over a decade ago, and efforts to improve interoperability continue with current developments. Shown here are some current interoperability initiatives from one morning’s mailbox. Data repositories will be connected to this debate, but so far it has not been a priority in the examples we have considered here.
Slide 25 One of the organisations listed on the previous slide, COAR, produced a report that outlines more comprehensively the scope of current interoperability initiatives for open access. While some solutions to the capture of research data seen here have reasonably been ‘architected’, that is, starting with a blank sheet to focus on the specific design needs of data deposit, these will need to catch up quickly with interoperability requirements, including most of those listed here. Data repositories ‘engineered’ on a platform such as EPrints, originally designed for other data types, do not obviously lack the flexibility to accommodate research data, and by virtue of having contributed to repository interoperability since the original OAI, already support most of the requirements shown here.
Slide 26 As for the DataPool Project, it will continue its dual approach of developing and testing both Sharepoint and EPrints apps. As a project it does not get to choose what is ultimately adopted to run the emerging research data repository at the University of Southampton. There are repository-specific factors that will determine that; but there are other organisational factors to take into account as well. Institutions seeking to build research data repositories that are clearly focussed on this range of factors are likely to have most success in implementing a repository to attract data deposit and usage.
This post has covered just one presentation, from DataPool, at RDMF9. The following two blog reports give a wider flavour of the event, the first exploring the architectural issues raised.
Julie Allinson, Some initial thoughts about RDM infrastructure @ York: “I’ll certainly carry on working up my architecture diagram, and will be drawing on the data coming out of our RDM interviews and survey to help flesh out the scenarios we need to support. But what I feel encouraged and even a little bit excited by is the comment by Kevin Ashley at the end of the RDMF9 event: that two years ago everyone was talking about the problem, and now people are coming up with solutions.”
Carlos Silva, RDMF9: Shaping the infrastructure, 14-15 November 2012: “Overall it was a good workshop which provided different points of view but at the same time made me realise that all the institutions are facing similar issues. IT departments will need to work more closely with other departments, and in particular the Library and Research Office in order to secure funding and make sustainable decisions about software.”