Architecting research data management systems
There seemed to be general surprise following the revelation that Damien Hirst does not always ‘make’ his own works of art. Instead he leaves production to assistants based on his ideas and designs. In effect, he architects his art. Similarly, high profile architects like Norman Foster or Zaha Hadid are no less creative forces if they are not also builders.
In the rather different world of managing research data (MRD) we need systems to manage these data, but given the range of different types of data and emerging requirements of data producers, their institutions and users, we should be careful about simply adopting existing systems or even systems designs. The options are potentially wide, and complex. Instead of the systems engineer, the stage we are at needs the systems architect to take a high-level view of all the requirements to produce an elegant solution, fit for purpose and designed for the environment in which it is to be placed.
So I was interested to see the architecture for a research data repository at the University of Bristol illustrated by the JISC data.bris project. The accompanying description starts with front-ends and storage architectures and on the way refers to various technologies. The key feature, however, seems to be the recognition that this service must integrate with existing institutional information systems – not a unique view perhaps among current JISC projects, but one taken into account in the high-level architecture at the outset rather than as an afterthought.
Another of our companion JISC MRD projects, DataFlow at Oxford University, is developing a data deposit architecture that attracted my attention at the MRD programme launch meeting in Nottingham in December last year. This features a two-stage approach – DataStage and DataBank – that recognise different motivations for data deposit by researchers: 1, for storage and management (mimicking the popular Dropbox approach) prior to 2, data publication and access. The first is driven by researchers themselves, while the second may be more often driven by formal requirements by funders, institutions and policies. Broadly, these stages might offer a simple deposit interface and a more formally structured metadata collection interface, respectively (although I wait to see whether this is what DataFlow provides). The point about this approach is that it supports, and links, both motivations for data deposit.
What does DataPool offer in terms of a data system architecture? At the same Nottingham meeting the project presented a poster (pdf) including a diagram of a proposed system architecture. For those that saw it this graphic may have caught the eye for the splash of colour it brought to the poster, but the viewing context was not ideal for detailed information. It is worth reproducing that illustration here with some reflection on what it might offer to the general architectural principles we need to establish for research data systems.
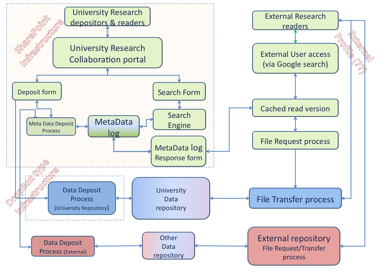
Adapting the Southampton Microsoft Sharepoint 2010 system for data deposit
This diagram was produced by Peter Hancock, director of iSolutions, the University of Southampton’s ICT professional services department. Continuing development of this data architecture will remain an iSolutions responsibility in parallel with and beyond the DataPool Project. Where DataPool comes in is to seek to connect the data system approach with other institutional interests, notably researchers and users, through case studies and faculty contacts; training, through staff and graduate training centres; and policy, through the university’s research advisory and decision-making groups.
What follows are some thoughts on this architecture. First, as with DataFlow, this appears to be a two-stage architecture, in this case indicated as ‘Sharepoint’ and ‘Dropbox type infrastructure’. Actually, it would be hard to compare this too closely with DataFlow, or even Dropbox, without some illustration of the respective deposit interfaces, and that is for another post.
This figure omits to connect other deposit interfaces, which could be EPrints or SWORD for example, with the University Data Repository and storage service. Such interfaces might be produced by DataPool or others, rather than by iSolutions, but these will still need access to the underlying university data infrastructure.
Second, there are two access routes for users, which can broadly be defined as internal and external to the institution. As this is a service-oriented architecture this is inevitable and presupposes a privileged view for internal users. Whether this privilege extends beyond their own work is under discussion.
Finally, deposit is not restricted to the institution’s repository but allows data to be moved and copied between institutional and external disciplinary or subject-based data repositories. This might be accomplished via a service such as SWORD. Research data policies promote such options, providing chosen data storage services are reputable and appropriate, rather than specifying particular data repositories, and many researchers wish to exercise such choice.
All institutional research data services will need to make provision for extensive and expanding data storage. This is not elaborated in the figure, and strategy, infrastructure and costs for this continue to be discussed at a high level.
The point of an architecture is that it becomes a detailed plan for building, or in this case implementing a research data system. Prior to that, as a high level abstraction it serves as a platform for input for all interested stakeholders, from all perspectives. For DataPool those perspectives span the whole of the University of Southampton, and to capture those we have ensured we shall be working across faculties, with the faculty contacts, and with data producers through disciplinary exemplars and case studies. Ultimately, to make progress this has to be an iterative process of development and feedback, but central to this is the development of the architecture because that is what should reach out to most people.
At this conceptual level an institutional data management architecture will raise many questions. We may or may not need Sharepoint, EPrints, DSpace and other information systems solutions; what we need are systems to fit the architectural vision.