What can research data repositories learn from open access? Part 2
Open access is finally attracting high-level attention from national governments, but full open access has been a long time arriving despite extensive funding, development and the commitment of many people. As much of that effort switches towards the implementation of repositories to store, share and publish the research data that informs publications, we are considering what lessons might be learned from open access repositories, so that the path to effective data repositories might be shorter and less fraught. In part 1 the factors considered included policy, infrastructure, workflow and curation. Here in part 2 we look at rights and user interfaces.

2500 Creative Commons Licenses
Rights
2500 Creative Commons Licenses
Since open access is indelibly associated with publication, one of the primary impediments to providing open access is transfer of rights to publishers, a practice that has failed to adapt to the digital switch. Research data is not so encumbered now, and with care data creators can deploy rights more effectively because they begin in the digital era.
It has often been argued that open access repositories failed to adopt or compete with Web 2.0 services. Quite what this means is not clear, but one aspect might be social and user engagement for the purpose of growing content. Well-known services that became associated with Web 2.0 are YouTube and Flickr, so the case might be that OA repositories were not as successful in attracting content as these services. There is one key point that differentiates these services from open access: prior to Web photo and video services, there were no simple publication outlets for this type of content for non-professional or non-broadcast works. In the case of open access there are pre-exisiting publications, such as journals and conference proceedings. Open access repositories do not seek to eliminate the journals, but to supplement the access they provide. There is thus another party with a vested interest in ownership of this content.
This is why open access can get mired in discussions about rights. Creative Commons (CC) licences were designed for content to be shared on the Web and communicate how creators are prepared to share their rights with users to open and extend use of their content. For research papers, however, since long before the Web, publishers have required a transfer of rights from the author in return for publication – hence the ownership issue. Unlike CC, these rights can be used to lock down access and reuse, for commercial purposes.
There is a form of open access, ‘gold’ OA journals (in BOAI this is complementary to ‘green’ OA repositories), which may be accompanied by release of commercial rights using CC but often at a cost for publication. In other words, publication is paid for financially rather than in a transfer of rights. Such journals present this as an advantage over non-OA journals and OA repositories, and this can be beneficial for text mining and other applications. While this form of OA publishing has been growing in recent years, it remains to be seen how quickly it can replace or adapt key high-impact journals, and at what cost.
Broadly, research data are not yet subject to publication rights. Publications are a highly processed form of research data, in the form of tables and graphs, for example. Typically the data targeted by data repositories precedes the refined and summarised publication versions, and is therefore not covered by the same rights transfer. That could change if expanded publications requiring data deposit or third-party service providers seek to obtain rights in return for these services.
Strictly, while institutions where research has been performed inherently own the rights to that work, they have been reluctant to exercise those rights in ways that would restrict a researcher’s choice of publication, or to require or even advise authors on some retention of rights or amendments to rights agreements. Unlike with peer reviewed papers, where precedent is more strongly established, it is possible that institutions will seek to impose more control of rights where research data is concerned. Recently reported cases show how a university’s allocation of control of rights within research teams, the special case at Purdue University notwithstanding, can have consequences for publication. What data creators and authors will be concerned about is whether the exercise of those rights by institutions is commensurate with the services that are provided in return. There may be resistance if established academic freedoms are constrained and research impact is reduced as a result, but with the right services and effective exercise of rights impact can be increased by sharing research data openly.
The lesson of open access is that rights matter, that the traditional all-rights transfer for academic publication is no longer appropriate for or conducive to fully exploiting new forms of digital dissemination, but also that established practices can be slow to change. Institutions and authors should be careful not to let rights to research data slip away as they did for publications in another era, but equally they must be careful to work together to use those rights in ways that maximise the benefits and impact for them and for research.
User interfaces
Users of repository services are both those who provide the data and those who consume it. The features that define and characterise repositories are the interfaces through which users can perform these actions, but are these interfaces flexible or adaptable enough to serve all those who might want to use repositories for publications or data?
Within this analysis (including part 1) it has been suggested that OA repositories may have overlooked workflow, and Web 2.0 developments with regard to content growth, services and engagement with users. In fact, some helpful developments can be found buried deep within repository software, but to see where these might impact users more directly we have to look away from the familiar repository interfaces. This critical development is called SWORD (Simple Web service Offering Repository Deposit), and it will impact on data repositories as well, in ways that we have not yet seen implemented on a large scale, even for OA repositories.
As the name indicates, SWORD is focussed on one of the actions that a repository supports, deposit, that is, getting new content into a repository or updating content, this updating feature recently becoming available with SWORD version 2.
SWORD frees the user deposit interface from the repository software and the specific instance of a repository. As the number and types of repositories have grown, some authors may wish to deposit in more than one place. SWORD can help with that. If the repository deposit interface demands too many keystrokes (metadata), or does not allow all the metadata you want to record – too few keystrokes, SWORD can help there as well.
The deposit still needs to reach a repository (‘endpoint’) so SWORD and repository softwares are working together on this, not competing. All major repository softwares support SWORD, and the most recent releases support SWORD v2. What’s needed are more SWORD client interfaces, as there have been relatively few examples to date.
It is easy to see that data repositories can benefit from SWORD in the same way as open access – deposit in many places from a single interface. When it comes to scoping metadata within a deposit interface, given the wide disparity in describing different data types in different disciplines with metadata, SWORD begins to appear essential for data deposit. These are just the services we can anticipate now.
With SWORDv2 we can envisage taking deposit out of the forms-based deposit approach and into different applications. One that may work for data deposit is a DropBox-like application for file-based deposit. With this application ‘dropping’ a file to a specified directory in a file manager on a laptop, say, synchronises and copies subsequent versions of that file to a repository (Figure 3), or potentially to a remote storage service, which can be accessed by the user logging on to the storage site using any Web-connected device. Data can thus be accessed and shared, or published in open access repositories. Using SWORDv2, file manager-based services could be used for simple deposit of research data files in conjunction with storage services; with SWORD v2 these could also fulfil automated deposit cases.
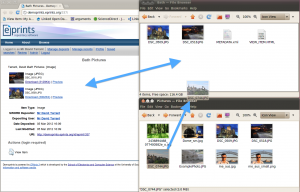
Figure 3. Dragging an image copies it to the selected repository
The DataFlow workflow illustrated in part 1 uses SWORD as the transfer mechanism between the user’s local storage and the curated institutional storage, in essence using it to capture additional metadata.
Another demonstrated application of a SWORDv2-based interface works within desktop authoring tools, such as a word processor or other office applications.
What these applications portend is that data repositories can fill the workflow gap, which we recognised was missing from open access repositories, and which looks to be potentially more complex for data repositories. We can begin to support deposit of data to a schedule that need not be based on the same frequency and mode as publication but is more flexible. As well as needing more SWORD client interfaces, however, another open question is how repository softwares designed for publication can adapt to support two different paradigms: managed storage as well as publication.
There are only two reasons for data creators to deposit in data repositories: they want to (share, publish, good academic practice, etc.), or they have to (policy). By focussing on services that are adaptable enough to serve users, building on SWORD to support flexible workflow and bringing deposit into automated or even more creative applications, research data repositories have the chance to support both motivations, instead of being left to emphasise policy as the primary motivator, as has happened for open access repositories.
Summary
Establishing and growing open access content is taking longer and proving harder than ever originally anticipated back in 2000. As we consider how to extend open access repositories to manage research data, are we learning the right lessons from open access? Have we covered all the important issues, or are we missing key factors? Research data repositories bring challenges that are distinct from open access. What are the new challenges, and which of these will have most impact on the success of research data repositories?
In this analysis the factors we have considered include policy, infrastructure, workflow, curation, rights and user interfaces. We haven’t covered preservation, but digital preservation is served by a comprehensive selection of tools that can be applied to repositories, and one lesson seems to be that repositories will move to be preservation-ready when content volumes and risk-analysis demand.
Open access began with the principle that it is good for researchers to share findings, and that digital networks enable that to happen more widely and at lower cost, ultimately free to users. It was anticipated that users would want to take advantage of this, as physicists already did with arXiv, and when this model failed to take off to the same degree in other disciplines, eventually institutional repositories emerged to encourage further growth of open access. As that growth appeared to hit a ceiling, research funders and institutions began to step in with open access policy. In other words, principle – whichever principle you prefer, returns to taxpayers, for example, or productivity of research, or escalating journal costs – was used to justify and frame policy for users. Users themselves, so it seems based on unmandated rates of open access deposit, have been less keen to put principle into practice.
In hindsight there are lessons that could have been learned to speed up the process. Progress with data repositories need not suffer the same mistakes or the same delays. Data repositories might occupy a more pragmatic, less emotional space than open access. Unlike for open access there is no single or easily defined target for research data repositories – what is data? continues to be a perennial question – so policy and requirements might be broader. Perhaps this time content deposited in data repositories can be driven by services that attract users, as well as by policy. In this case, the aim of data repositories must be find those users who want these services, and then to make those services work better for them.